






XML es un lenguaje de marcas que se ha estandarizado y se ha convertido en uno de los formatos más populares para intercambiar información.
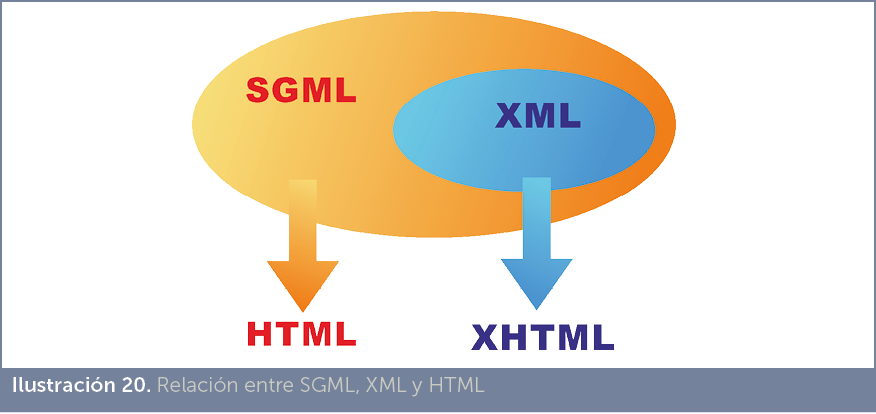
Se trata de un formato de archivos de texto con marcado que deriva del lenguaje SGML, y que ha establecido una serie de reglas más estrictas, pero más fáciles y coherentes.
La realidad es que XML siempre ha estado muy ligado al éxito de HTML. Su aparición se justifica por los problemas crecientes que se fueron observando en las páginas web.
El lenguaje HTML, propio de las páginas web, a finales de los años 90 tenía estos problemas como formato de intercambio de información:
Pero existían otras etiquetas que no son semánticas. Así font, sirve para colorear o cambiar el tipo de letra y no para indicar qué tipo de texto tenemos.
Por ello al crear XML se plantearon estos objetivos:
[1] Debía de ser similar a HTML (de hecho se basa en el lenguaje SGML base para el formato HTML), dada su enorme aceptación.
[2]Debía de ser extensible, es decir que sea posible añadir nuevas etiquetas sin problemas. Esa es la base del lenguaje XML.
[3] Debía de tener unas reglas concisas y fáciles, además de estrictas.
[4] Debía de ser fácil de implantar en todo tipo de sistemas. XML nace con una vocación multiplataforma, como base de intercambio de información entre sistemas de toda índole.
[5] Debía ser fácil de leer para todas las personas.
[6]Debía ser fácil crear herramientas capaces de procesar XML
Básicamente XML es SGML. Es decir, una persona que conozca SGML no tendrá ningún problema en aprender XML. Las bases son las mismas, pero XML elimina gran parte de su complejidad. De hecho se dice que XML es un subconjunto de SGML. Es decir, es SGML pero restringiendo o eliminando ciertas normas.
Por otro lado XML sirve para lo mismo que SGML: para diseñar lenguajes de marcas. Es decir, XML define tipos de documentos, de forma que, junto a la información del documento, hay una serie de etiquetas que sirven para clarificar lo que significa la información.
De esa manera XML (como ya hizo SGML) es un lenguaje que permite especificar otros lenguajes. Entendiendo como lenguajes, en este caso, al conjunto de etiquetas que se pueden utilizar en un documento. No solo qué etiquetas, sino en qué orden y de qué forma se pueden utilizar.
Algunos de los lenguajes estándares de marcado basados en XML son:
XML fue defendido por Tim Bernes-Lee el creador de la web. La idea era que acabara retirando a HTML como formato principal de los documentos de la web.
De hecho XHTML, durante un tiempo, fue el HTML aceptado por la comunidad de desarrolladores web. XHTML es un lenguaje creado bajo las normas de XML.
Sin embargo, el triunfo de HTML 5 ha limitado completamente esta idea. Ahora XHTML no tiene, prácticamente, ninguna influencia. forma se pueden utilizar en el documento.
El hecho de que XML almacene información mediante documentos de texto plano, facilita que se utilice como estándar, ya que no se requiere software especial para leer su contenido: es texto y es entendible por cualquier software.
Numerosos servicios en Internet ofrecen resultados de consultas en este formato. Entre ellos el tiempo, resultados de elecciones, datos estadísticos, consultas a bases de datos, etc.
Es un formato muy defendido para almacenar documentos. Su simplicidad y gran capacidad semántica son la clave del éxito en este tipo de usos. El formato documental basado en XML más famoso es el formato ePUB, el más utilizado como formato de eBooks.
Como formato documental para las empresas es muy interesante por su versatilidad y facilidad de manipulación.
Todas las grandes bases de datos empresariales son capaces de utilizar XML para extraer datos o incluso como formato fundamental de algunos sistemas gestores de bases de datos. Lenguajes como XQuery o XPath permiten encontrar o navegar entre los datos de un documento XML.
Las principales bases de datos incluso tienen a XML como un posible formato para sus atributos o columnas, de modo que se pueden almacenar directamente en ellas y luego utilizar técnicas de búsqueda de información propias de XML para extraer la información que nos interese.
En estos últimos años, el formato SVG es reconocido por todos los navegadores. SVG es un lenguaje XML que sirve para representar imágenes vectoriales. AL ser imágenes que no pierden calidad al ampliar o reducirse, se han convertido en las ideales para los logotipos, líneas, formas e iconos de las páginas.
Para almacenar información de configuración o de archivos tipo log (archivos que graban los eventos ocurridos en un determinado dispositivo) de diversos aparatos hardware, es también un formato ideal.
Numerosos switches, routers, impresoras o servidores utilizan el lenguaje XML para este tipo de archivos. De esa forma la información se estructura de forma muy semántica y es muy sencillo modificar la configuración de estos aparatos.
El ecosistema XML aporta un gran número de tecnologías y lenguajes (la mayoría de lenguajes están también basados en XML) para conseguir obtenener más funciones de los documentos XML.
Las tecnologías más importantes son:
En principio XML se puede escribir desde cualquier editor de texto plano (como el bloc de notas de Windows o el editor vi de Linux). Pero es más interesante hacerlo con un editor que reconozca el lenguaje y que además marque los errores en el mismo.
Además las distintas funciones habituales que se realizan con los documentos XML, requieren de otro software capaz de manipular el contenido de los documentos. El software necesario, habitual, es el siguiente:
[1] Un editor de texto plano para escribir el código XML. Bastaría un editor como el bloc de notas de Windows o el clásico vi de Linux.
Pero hay editores mucho más apropiados. Son los editores de código de múltiple propósito. Son editores que colorean el código especial porque conocen casi todos los lenguajes (C, Java, Python, HTML,etc.). Ejemplos de ellos son emacs, Notepad++ o SublimeText.
[2] Un analizador sintáctico o parser, programa capaz de entender y validar el lenguaje XML. Apache Xerces es quizá el más popular validador de documentos XML.
[3]Un procesador XML. Software capaz de producir una presentación visual sobre el documento XML. Un simple navegador puede hacer esta función, pero cuando se aplican lenguajes de presentación como CSS.
Pero hay software que transforma los documentos XML mediante el lenguaje XSL, para producir resultados, por ejemplo, en HTML.Apache Xalan y Saxon son los dos procesadores de XSL más conocidos

Hay entornos de trabajo que incluyen todas esas prestaciones dentro del mismo paquete software. Es el caso de Oxygen o WebStorm por ejemplo.
Los documentos XML, en definitiva, son documentos de texto cuyos metadatos se indican mediante etiquetas (marcas) que permiten clasificar el texto a través de su significado.
Las etiquetas en XML se deciden a voluntad, no hay una lista concreta de etiquetas que se pueden utilizar. La idea es que con XML estamos definiendo un tipo de documento cuya forma, significado y estructura dependerán solo de nuestras necesidades.
Ejemplo de XML:
<persona> <nombre>Jorge</nombre> <apellido>Sánchez</apellido> </persona> |
En este código, se define un elemento llamado persona, que contiene a dos elementos más: nombre y apellido, cuyos valores son Jorge y Sánchez respectivamente.
Algunos detalles sobre el funcionamiento son:
Los documentos XML se dividen en:
En XML los elementos y atributos tienen un nombre (más correctamente llamado identificador), el cual debe cumplir estas reglas
Se trata de la primera línea de un documento XML y sirve para clarificar el tipo de documento XML. En realidad es opcional, pero es muy recomendable. Es:
<?xml version=”1.0” encoding=”UTF-8”?> |
Indica la versión XML del documento (se suele usar 1.0) y la codificación (utf-8 es la habitual y recomendable por la W3C).
Un documento XML puede incluir instrucciones de este tipo para indicar un documento para validar el XML, darle formato,… u otras funciones. Por ejemplo:
<?xml-stylesheet type=”text/xsl” href=”stylesheet.xsl”?> |
Esta instrucción asocia un documento xsl al documento XML para poder darle un formato de salida (para especificar la forma en la que los datos se muestran por pantalla por ejemplo).
Como se ha indicado antes comienzan con el símbolo <!-- y terminan con -->. Dentro puede haber cualquier texto que se utiliza con fines explicativos o de documentación del código.
Los comentarios no pueden meterse dentro de la etiqueta de un elemento, ni tampoco puede contener etiquetas ni de apertura ni de cierre.
Son la base del documento XML. Sirven para dar significado al texto o a otros elementos o también para definir relaciones entre distintos elementos y datos.
Hay una confusión entre lo que es un elemento y lo que es una etiqueta. En este caso por ejemplo:
<nombre>Jorge</nombre> |
El contenido de un elemento puede contener simplemente texto:
<descripción> Producto con precio rebajado debido a su escasa demanda </descripción> |
O puede contener otros elementos (o ambas cosas). En este el elemento persona consta de un elemento nombre y otro apellido.
<persona> <nombre>Jorge</nombre> <apellido>Sánchez</apellido> </persona> |
Los elementos se deben abrir y cerrar con la etiqueta que sirve para definir el elemento. Siempre se debe cerrar el último elemento que se abrió. Es decir es un error:
<persona><nombre>Jorge</nombre> <apellido>Sánchez</persona></apellido> |
Los elementos vacíos no tienen contenido. Ejemplo:
<casado></casado> |
Los elementos vacíos pueden indicar el cierre en la propia etiqueta de apertura:
<casado /> |
Se definen dentro de las etiquetas de apertura de los elementos. Sirven para indicar propiedades de los elementos a los que se les asigna un determinado valor.
Para ello se indica el nombre del atributo seguido del signo = y del valor (entre comillas) que se le da al atributo. Ejemplo:
<persona complejidad=”alta”> <nombre>Jorge</nombre> <apellido>Sánchez</apellido> </persona> |
Un elemento puede contener varios atributos:
|
<persona privacidad=”alta” tipo=”autor”> <nombre>Jorge</nombre> <apellido>Sánchez</apellido> </persona> |
El texto como se comentó antes está siempre entre una etiqueta de apertura y una de cierre. Eso significa que todo texto es parte de un elemento XML.
Se puede escribir cualquier carácter Unicode en el texto, pero no es válido utilizar caracteres que podrían dar lugar a confusión como los signos separadores < y > por ejemplo
Existe la posibilidad de marcar texto para que sea procesado lieralmente como texto y no como sintaxis de XML. Eso permite indicar texto que contiene caracteres que serían problemáticos. Para ello, el texto se coloca dentro de un elemento CDATA. Este elemento funciona así
<! [CDATA [ texto no procesable… ]]> |
Esto permite utilizar los caracteres < y >, por ejemplo, dentro de un texto literal y no serán considerados como separadores de etiquetas.
Ejemplo:
<?xml version=”1.0”?> <documento> <título>Prueba</título> <ejemplo> <![CDATA[ En HTML la negrita se escribe: <strong> ]]> </ejemplo> </documento> |
En el ejemplo, los símbolos < y > no se toman como una etiqueta XML, sino como texto normal.
Otro uso de CDATA es colocar dentro de este elemento código de lenguajes de scripts como Javascript para que no sean interpretados como parte de XML.
Las entidades representan caracteres individuales. Se utilizan para poder representar caracteres especiales o bien caracteres inexistentes en el teclado habitual. Se trata de códigos que empiezan con el signo & al que sigue el nombre de la entidad o el número Unicode del carácter que deseamos representar.
En XML hay definidas cinco entidades:
Es obligatoria usar esas cinco entidades en lugar de los símbolos que representan.
También podemos representar caracteres mediante entidades con número. De modo que el ñ representa a la letra ñ (suponiendo que codificamos en Unicode, que es lo habitual). El número puede ser hexadecimal por ejemplo para la eñe de nuevo, sería ñ
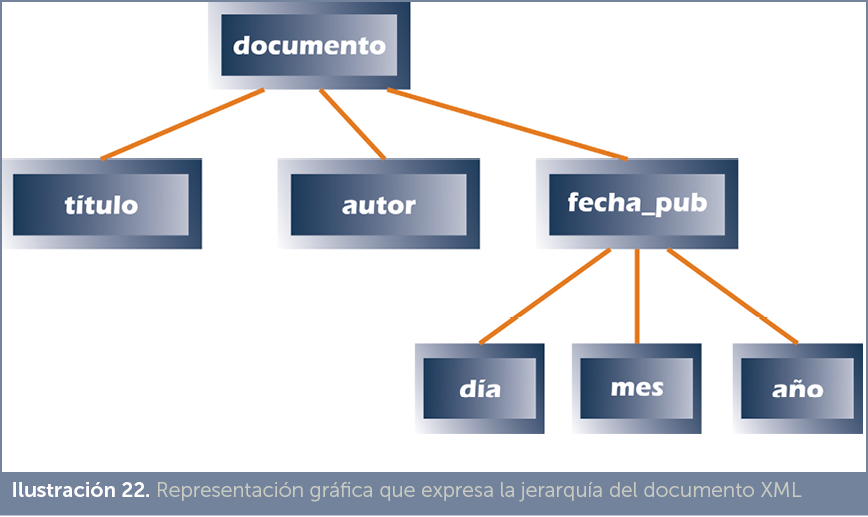
Los elementos de un documento XML establecen una jerarquía que estructura el contenido del mismo. Esa jerarquía se puede representar en forma de árbol.
Así por ejemplo el archivo XML:
<?xml version=”1.0” ?> <documento> <título>Apuntes de XML</título> <autor>Jorge Sánchez</autor> <fecha_pub> <día>18</día> <mes>Enero</mes> <año>2009</año> </fecha_pub> </documento> |
Este documento se puede representar de esta forma gráfica:
Se habla de XML bien formado (well formed) cuando el documento cumple reglas estrictas, las cuales están pensadas para facilitar su legibilidad y mantenimiento. Además permiten cumplir los objetivos que se plantearon los creadores del lenguaje XML
Debemos tomar las reglas para producir XML bien formado como reglas obligadas. Los documentos XML que no están bien formados, se les considera incorrectos y así serán marcados por los analizadores (parsers) de XML que se encargan de comprobar la sintaxis de los documentos XML.
Un documento XML bien formado es un documento analizable. Sin embargo eso no significa que sea válido. Los documentos válidos cumplen la sintaxis de un documento validador, idea que se explicará en la siguiente unidad.
En los siguientes apartados se explica las reglas que deben de cumplir los documentos bien formados.
Es decir, este código no sería XML bien formado:
<fecha><dia>13</dia><mes>Mayo</fecha></mes> |
Lo correcto sería:
<fecha><dia>13</dia><mes>Mayo</mes></fecha> |
Todos los elementos poseen etiquetas de apertura y de cierre. Es decir, toda etiqueta que se abra se debe de cerrar. Si la etiqueta no tiene contenido, se debe cerrar en la propia etiqueta. Por ejemplo:
<br /> |
<nombre sexo=”Hombre”>Antonio</nombre> <nombre sexo=’Mujer’>Sara</nombre> <nombre sexo=’Mujer”>Eva</nombre> <!-- error --> |
La última línea es incorrecta porque no se pueden combinar ambas comillas.
<hr noshade> |
Debería ser, por ejemplo, así:
<hr noshade=”noshade”> |
Para comprobar si un documento XML está bien formado, necesitamos un software de validación. Posibilidades:
[1]En el caso de Windows, hay que descargar la librería libxml2 de la dirección ftp://ftp.zlatkovic.com/libxml/ y desde ahí descargar los zip necesarioselegir el archivo ZIP de la librería con la última versión (en el momento de escribir estas líneas es el archivo libxml2-2.7.8.zip)
[2]Descomprimir el archivo en el sitio deseado y asignar en la que viene dicho validador (lo normal es descargar un archivo ZIP en el caso de Windows y descomprimirlo).
Puede ocurrir que cuando se manejan diversos documentos XML que varios de ellos utilicen las mismas etiquetas, aunque el contexto sería distinto. De ser así, tendríamos un problema si manejamos ambos documentos con el mismo software, ya que el analizador, no sabría cómo manejar ambas etiquetas iguales.
Los espacios de nombres (namespacing en inglés) evitan el problema indicando en cada elemento una indicación que sirve para indicar el contexto de cada etiqueta y así diferenciar las que son iguales. Ejemplo:
<?xml version=”1.0” encoding=”UTF-8”?>
|
En el ejemplo anterior se usan etiquetas en inglés para el documento (algo muy habitual en el mundo empresarial) y eso hace que la etiqueta title se repita en contextos distintos; la primera aparición es para poner un título genérico al documento (y es una etiqueta de la empresa en cuestión) y la segunda se corresponde a la etiqueta title del lenguaje HTML.
La solución para diferenciar es anteponer al nombre de la etiqueta un nombre distintivo separado por un punto.
Por ejemplo:
<?xml version=”1.0” encoding=”UTF-8”?>
|
Ese prefijo diferenciador es el espacio de nombres al que pertenece la etiqueta, pero usado así tendríamos el problema de que con un sufijo tan corto, se podría repetir.
Por ello una solución más completa, es indicar la URL de la entidad responsable de la etiqueta:
<?xml version=”1.0” encoding=”UTF-8”?> |
Como se puede observar, el documento ahora es muy poco legible.
La complejidad del código anterior nos traslada el por qué necesitamos de otra solución más simple pero igual de definitiva.
Los espacios de nombres permiten indicar un prefijo a las etiquetas. A ese prefijo se le asocia una URL. De este modo el nombre es único, pero, a la vez, el código no es tan complejo. El prefijo se separa con dos puntos del nombre.
La URL que se asocia es en realidad una URI (Universal Resource Identifier) un identificador único de recurso, de modo que la raíz de la URI es el dominio universal (Internet) de la empresa y a él se añade la ruta al recurso. Así si hemos definido documentos XML cuyo elemento raíz es document, la URL relacionada con el espacio de nombres del documento podría ser:
www.jorgesanchez.net/document.
Todas las etiquetas en XML pueden hacer uso del atributo xmlns (xml namespacing) que permite asignar un espacio de nombres a un prefijo en el documento dentro del elemento en el que se usa el espacio de nombres. Ejemplo:
<?xml version=”1.0” encoding=”UTF-8”?> xmlns:jorge=”http.//www.jorgesanchez.net/document” xmlns:html=”htp://www.w3c.org/html”> <jorge:title> </html:head> </jorge:content> |
En el ejemplo se usa el prefijo jorge para indicar etiquetas del espacio de nombres www.jorgesanchez.net/document y html para el espacio de nombres oficial de HTML.
En el caso de que las etiquetas, mayoritariamente, en un documento pertenezcan a un mismo espacio de nombres, lo lógico es indicar el espacio de nombres por defecto. Eso se hace sin indicar prefijo en el atributo xmlns. Ejemplo:
<?xml version=”1.0” encoding=”UTF-8”?> xmlns=”http.//www.jorgesanchez.net/document” xmlns:html=”htp://www.w3c.org/html”> <title> </html:head> </content> |
Las etiquetas sin prefijo se entiende que pertenecen al espacio de nombres www.jorgesanchez.net/document, para las del otro espacio se usa el prefijo.
El atributo xmlns no tiene por qué utilizarse en el elemento raíz, se puede posponer su declaración en el primer elemento que pertenezca al espacio de nombres deseado. Por ejemplo:
<?xml version=”1.0” encoding=”UTF-8”?> xmlns=”http.//www.jorgesanchez.net/document”> |
<content> </content> |
Un documento puede declarar espacios por defecto en etiquetas interiores lo que permite aún más versatilidad en los documentos.
Ejemplo:
<?xml version=”1.0” encoding=”UTF-8”?> <!-- comienza el espacio de nombres de jorgesanchez.net --> <body> |
<!-- fin del espacio html, regresa el espacio
</content> |
Si se usa el atributo xmlns=””, entonces se está indicando (en el interior del elemento en el que se use) que ese elemento y sus hijos no usan ningún espacio de nombres.